Multilevel Fault-tolerant Mechanism Design for MEMO Decentralized Cloud Storage System
This content is provided by a sponsor
The quality of fault-tolerant mechanism is a significant indicator of the performance of a computer system.
In the field of data storage, fault-tolerant mechanism refers to a technology by which the system can automatically restore the damaged or lost data to the state prior to the accident in the event of data damage or loss in the system.
With globally distributed edge devices as nodes, the decentralized storage system is open to great challenges in reliability and security due to the characteristics of P2P (point-to-point) environment and low credibility. Therefore, the design of fault-tolerant mechanism appears to be of particular importance.
Common Technologies of Fault-tolerant Mechanism
There are two common technologies of data fault tolerance, namely the multi-copy technology and the erasure coding technology.
Multi-copy Technology
The multi-copy technology operates by generating multiple backup copies of original data and storing them separately at multiple distinct storage nodes. In the case that some nodes are unusable, the data at other nodes can be used for operation, which greatly boosts the reliability of the storage system. Multi-copy processing is also very simple and takes the mere effort of copying replica data from the existing nodes to the newly added ones.
The advantages of multi-copy technology are ease of use, high stability, and convenience in maintenance. However, its shortcomings are also obvious. As storing multiple copies increases storage overhead significantly, the burden becomes significant when the size of stored data reaches PB or even EB, which also increases the electric power overhead and space overhead of hardware devices, etc.
Erasure Coding Technology
Erasure coding is a technology that splits data into segments before extending, encoding and storing the redundant data blocks at distinct positions.
The fundamental of erasure coding is to segment a transmitted signal, give it some control, and then create certain relation between the segments. Even if a portion of the signal is lost through the transmission process, the receiving terminal remains capable of generating the complete information through algorithms. It is clear that erasure coding technology is being applied more to transmission rather than storage.
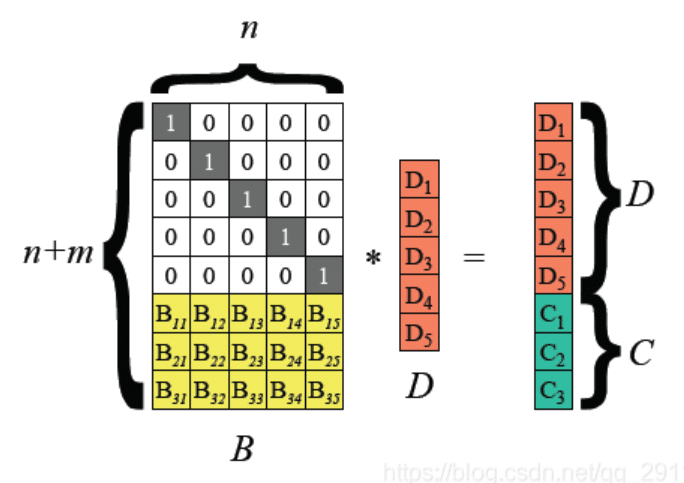
RS is the most classic erasure code and it operates according to the following principle: First, splits the stored data into k original data blocks of equal size, denoted as (D1, D2, …, Dk). Next, calculate n redundant data blocks, denoted as (C1, C2, …, Cn), for these original data blocks in accord to a fixed encoding rule. These (k+n) data blocks are called a strip. The fault-tolerant mechanism of RS code is such that for k arbitrary data blocks downloaded of a same stripe, all the data blocks of this stripe can always be restored through some decoding algorithm.
Figure: Schematic Diagram of Erasure Coding
For its advantage of low spatial consumption, erasure coding has become the most common technology in current distributed storage systems. However, it is too costly to restore when compared to the multi-copy technology. Hence the restoring process of erasure coding is a degraded reading process, wherein the data blocks read during restoration are typically multiple times as many as the lost data blocks.
The Fault-tolerant Technology of Filecoin and Storj
Practically, no technology is made perfect. While the high-tolerance of multi-copy technology brings forth a high degree of redundancy; the erasure coding technology has a low degree of redundancy, but a lower level of efficiency in data reading and restoration.
For instance, the multi-copy technology is the only option of fault-tolerance for all files in Filecoin network. For instance, all files in the Filecoin network can only be fault-tolerant by using multi-copy technology, and complex data sealing mechanisms are designed for chain and mining security, which makes storage and download often take hours, causing rather low usability.
Storj, in turn, has chosen to use erasure coding as a redundancy mechanism. It encrypts files, uses erasure coding for fault tolerance, and then spreads the original data with the calibration data into the storage nodes. Although the data is stored in a decentralized pattern, Storj uses a centralized metadata storage system dedicated to saving metadata, that is the satellite node of Storj. Moreover, the data verification scheme used by Storj does not support open verification, so users cannot but believe unconditionally in the verification result of the satellite node. On the other hand, since funds settlement is entirely performed by the satellite node, storage nodes depend on it for seamless earnings distribution, which exposes Storj to the potential risks of single point failure and credence. On top of that, overload on the satellite node would also result in lowered service capability and reduced data storage and reading rates.
Design Objectives of the Fault-tolerant Mechanism of MEMO
Considering that Filecoin and Storj are both under certain tests of security, usability and reliability, the original design intention of the fault-tolerant mechanism of MEMO is the hope that a fault-tolerant mechanism with higher reliability, usability and security can be designed.
Therefore, MEMO has set the following goals in fault-tolerant mechanism design:
Achieving the lowest possible redundancy
Improving fault-tolerance at its best
Optimizing restoration performance
Guaranteeing consistency
In order to meet all goals above, namely to minimize the redundancy of the entire fault-tolerant mechanism while ensuring security and reliability.
MEMO’s definitive design is a multilevel fault-tolerant mechanism, with high-redundancy multi-copy fault tolerance as the primary mechanism, and low-redundancy erasure coding fault tolerance as the secondary mechanism. Also, on the basis of the volumes and application characteristics of all data, erasure coding-based fault-tolerance is fully adopted for data with larger volume, whereas multi-copy-based fault-tolerance can be adopted for data with smaller volume.
Characteristics of Three Sorts of Data in MEMO System
The fault-tolerant mechanism designed by MEMO operates these three types of data: basic mapping relational data, metadata, and data.
Basic mapping relational data (smart contract): Data which are used to express a storage protocol being achieved among the parties of user, intermediary, and storer. Basic mapping relational data are small and stable. They specify user’s requirements in the storage protocol, the number of intermediary and storing parties, the determined price for storage and other basic information, pertaining to the most elementary data type in the decentralized storage model.
Metadata refers to the attribute information of data, specifying the storage position, modification time, permissions and other information about the data. It is not until metadata are accessed that the data uploaded by the user party can be found. Metadata features small volume, low-frequency of modification, and frequent reading.
Data refers to the actual data stored by the user on the storage side, these data occupy the largest part of the decentralized storage model and give meaning to it. Data are characterized by their large volume and frequent changes.
Design of MEMO Fault-tolerant Mechanism
Utilizing the distinct characteristics of each sort of data, the Memolabs R&D team has designed a multilevel processing mechanism, aiming at promoting the cost performance of fault-tolerance while ensuring the security of data.
Fault-tolerance Design of Basic Mapping Relational Data
Basic mapping relational data are essential. They determine a service model, point at the right nodes for data storage and the referential nodes for the management node to verify. Hence the fault-tolerant mechanism of basic mapping relational data needs to allow for both integrity and reliability.
Integrity design: MEMO decentralized cloud storage system saves basic mapping relational data onto the blockchain. Due to the inherent traceability and tamper-proof properties of blockchain, the Hash value of each block in a blockchain depends on the Hash value of the previous block. This way, block interconnection is ensured, and ultimately, an integral chain from the initial to the current block is established. Any data in the blocks can be traced back to the source. When a faulty node is found to change data in a certain block on the blockchain, this means that all blocks starting from this one must be modified. Hence it is almost impossible to change the information about the blocks on a blockchain. Therefore, it is the basic mapping relational data saved in blocks which guarantees block integrity as these data are tamper-proof.
Designed for reliability. Basic mapping relational data is designed with multi-copy fault tolerance as it provides low restoration traffic and no computational overhead. Moreover, this type of data need to be read frequently and occupy relatively small storage space (not exceeding the KB level), and its repeatability requires minimal restoration costs. Therefore, multi-copy processing is ideal for basic mapping relational data.
Fault-tolerant Mechanism of Metadata
Metadata play the essential role of describing the user party’s data attributes, as well as pointing at the storage position, historical data, and resources searching, among others. The fault-tolerant mechanism design of metadata equally calls for consideration on both aspects of integrity and reliability.
Designed for integrity. To avoid the tampering of metadata , storage proof is used for a thorough data verification process that is performed as data are read. Since this authentication scheme has the characteristics of low data transfer and fast authentication, it is ideal for use in low-trust environments such as P2P. If, however, the Hash-value-based verification method is adopted instead, due to the incredibility characteristic of all nodes in the low-credibility environment, the verified party would have to transmit all data. An excessive amount of data to be verified could cause a tremendous impact on the storage network, or even result in a breakdown.
Data verification is needed when the user downloads stored data, when the management node needs to restore lost data or metadata, or when challenges to data or metadata are performed. In order for the verification process to go on smoothly, storage proof and verification are also a must when data and metadata are being uploaded.
Designed for reliability. To prevent the loss of metadata, they are processed with fault-tolerance, using multiple copies which are saved on the storage side nodes. Metadata are read and updated more frequently in the system, therefore, the use of erasure coding tolerance would result in very high read latency and cumbersome updates because the metadata would have to be restored first. However, the whole update process is simplified as metadata restoration is avoided with the use of multi-copy fault tolerance.
Fault-tolerant Mechanism of Data
User data are not only the data that take up the highest proportion in the entire system but also the data closely related with the user party’s experience.
Designed for integrity. Due to the differences in volume and functionality between data and metadata, which are both stored at the storage layer of the decentralized storage model, (i.e. in a low-credibility environment), they both share the same integrity design and need for data validation. The fault-tolerant mechanism, as well as the strategy of storage proof and verification used for metadata also apply to data.
Designed for reliability. Considering that user demands are diverse, data can be processed by either the multi-copy fault-tolerant method or the erasure coding fault-tolerant method. In this case, it is the user party’s choice. In order to lessen storage overhead, under the precondition that the user party has no definite option of fault-tolerance methods, data shall be processed by the erasure coding fault-tolerance method by default. An advantage of this practice is to lessen the storing party’s storage overhead. The storage cost on the storage side is more important than that of the degraded reads for erasure coding.
Data Restoration Mechanism
To improve restoration performance based on multi-level fault tolerance, MEMO considers these three aspects: recovery parallelism, recovery network, recovery timing selection. Delayed restoration strategies, parallel restoration strategies, and optimization as well as identification of the lost data block processes are used to improve the restoration performance of the whole fault-tolerant mechanism.
MEMO has created the unique RAFI (Risk Aware Failure Identification strategy, which optimizes the two steps known as risk classification and identification strategy. In risk classification, RAFI classifies risks no longer in terms of the number of lost data blocks in the strip but in terms of the number of invalidated data blocks in it. The invalidated data blocks refer to the owned lost data blocks and unusable data blocks. Under this classification, it is possible to reduce the probabilities of data becoming unusable and getting lost effectively. While on the identification strategy, RAFI’s core design principle is that the higher the number of block with failures a strip has, the faster such blocks are identified. In other words, different timeout thresholds are set for strips with different risk levels. This way reliability and usability are improved.
The RAFI strategy is adopted for failure identification. From this step to failure restoration, the strategy of delayed restoration is adopted. The last step of the restoration process is then performed according to the fault-tolerant strategy used for such data.
Summary
The multilevel fault-tolerant mechanism is a great groundwork for MEMO decentralized cloud storage system to ensure data integrity and reliability. MEMO is designed in a hierarchical way, and it adapts to the characteristics of each type of data, combining multi-copy technology and code-correction technology in parallel. MEMO seeks to find an optimal balance between reliability, security and redundancy. In addition, MEMO utilizes RAFI and delayed restoration strategies to enhance data restoration efficiency, allowing the optimal enhancement of the system in terms of security, reliability and availability.
Disclaimer: This publication is sponsored. Coinspeaker does not endorse or assume responsibility for the content, accuracy, quality, advertising, products, or other materials on this web page. Readers are advised to conduct their own research before engaging with any company mentioned. Please note that the featured information is not intended as, and shall not be understood or construed as legal, tax, investment, financial, or other advice. Nothing contained on this web page constitutes a solicitation, recommendation, endorsement, or offer by Coinspeaker or any third party service provider to buy or sell any cryptoassets or other financial instruments. Crypto assets are a high-risk investment. You should consider whether you understand the possibility of losing money due to leverage. None of the material should be considered as investment advice. Coinspeaker shall not be held liable, directly or indirectly, for any damages or losses arising from the use or reliance on any content, goods, or services featured on this web page.